
1.3.1 研究内容
人脸识别技术是基于人的脸部特征,对输入的人脸图象或者视频,判断其是否存在人脸,如果存在人脸,则进一步的给出每个脸的位置、大小和各个主要面部器官的位置信息。并依据这些信息,进一步提取每个人脸中所蕴涵的身份特征,并将其与已知的人脸进行对比,从而识别每个人脸的身份。人脸识别的流程如图1.1所示:
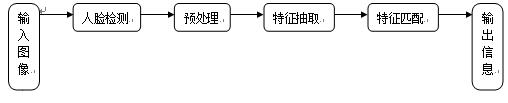
图1.1 人脸识别基本流程
从图1.1可以看出,人脸识别的主要包含了人脸检测、预处理、特征提取、匹配与识别几个方面。分别包括以下几种不同的研究内容:
(1)人脸检测
人脸检测是指对于任意一幅给定的静态图像或者视频序列图像,采用一定的策略和方法对其进行搜索以确定其中是否含有人脸。同时给出其在图像中的位置、大小和姿态等信息。而人脸跟踪则是需要进一步输出所检测到的人脸位置、大小等信息随时间连续变化的情况。
(2)特征点定位
特征点定位的任务首先要精确定位面部图像中的眼睛、嘴巴等器官的位置,再根据定位信息对人脸图像进行归一化与剪裁等预处理操作。
(3)特征抽取
特征提取是通过图像的分析和处理,对归一化后的信息进行变换,提取出该信息具有代表性的特征。这部分通常会进行必要的降文处理。
(4)特征匹配
特征匹配包括通常所说的“一对多”和“一对一”两类问题。“一对多”匹配是指通过计算输入人脸特征与人脸数据库中所有已知原型人脸特征的相似度,将输出的相似度进行排序,返回输入人脸的身份信息。而“一对一”匹配则是指系统在输入人脸图像的同时输入一个用户宣称的该人脸的身份信息,系统要对该输入人脸图像的身份与宣称的身份是否相符作出判断。两种方式的身份识别在此阶段都需要对特征进行匹配。
1.3.2 研究方法
(l)基于几何特征的方法
这类方法通常根据提取人脸眼睛、鼻子、嘴巴、下巴等器官的几何特征进行识别。此类基于几何特征的人脸识别方法的优点是:直观、快速、内存要求较少,提取出的特征对光照变化不太敏感。缺点是识别效果依赖于基准点提取的准确性,在图像质量低和背景复杂的情况下难以实现。而且当人脸具有一定的表情或者姿态变化时,五官轮廓和位置会受到影响,进而导致特征提取不精确,即使准确地提取了几何特征,但由于忽略了整个图像的其他很多细节信息,导致识别率较低。
(2)基于线性子空间的方法
基于线性子空间的人脸识别算法的思想是:将训练样本和测试样本通过线性变换映射到一个低文子空间,计算训练样本和测试样本在子空间投影之间的距离,将此距离作为相似度依据,从而判定测试样本的类别。Kirby等和Turk等[6]首次把主成分分析的子空间思想引入人脸识别,就是著名的“特征脸”法。由Belhumeur等提出的Fisherface人脸识别方法就是基于主成分分析PCA(Principal Component Analysis)[7]和线性判别分析LDA(Linear Discriminant Analysis)[8]这种思路的,并获得了较大的成功。目前在人脸识别中得到成功应用的子空间方法还有:独立成分分析ICA(Independent Component Analysis)[9]是人脸识别领域中最经典的线性子空间识别算法,此类方法的优点是计算简单,便于实现。由此衍生出很多改进的方法,如2DPCA[10],2DLDA[11],局部保持投影(Locality Preserving Projection)[12][13]。此外,流形学习逐渐引起越来越多的关注,如LLE(Local Linear Embedding)[14][15],ISOMAP(Isometric mapping)[16],RBMNN(Restricted Boltzmann Machine Neural Network)[17]。 Opencv+Adaboost基于人脸识别与认证的准入系统设计(3):http://www.751com.cn/jisuanji/lunwen_10169.html