- 上一篇:基于Kinect的人体检测系统设计与实现
- 下一篇:面向Web服务描述的本体到代数规约转换技术研究
在当今社会,互联网技术的迅速发展,给科学农业的进步带来了极大的推动作用。如今,对农作物的管理监测,只需要在田间放置大规模的传感器网络,农民在家就可以对农作物进行实时监测。这种方式大大提高了农民管控农作物生长状况的效率。但随着数据量指数级的增长,普通服务器在数据处理上越来越不能适应日益增长的数据,利用Hadoop云平台计算处理的思路便应运而生。本课题是学校与江苏农科院合作的省支撑项目,旨在实现基于大数据量下的高性能农作物云监测平台。
1.2 发展与研究现状
1.3 课题研究主要内容
实现一个提供给农民用户使用的传感器数据监测平台,这各平台在架构上包括一个信息监测网站,以及针对大数据量下可以极大提高信息处理效率的Hadoop集群。
1)网站主要提供给用户:
1.实时数据,历史数据的查询功能,结合图、表,展示清晰,内容明确。
2.用户可以在网站上进行对各个传感器的管理,包括添加,删除,开关等。
2)使用Hadoop集群存储大文件,以及处理大量的日志文件。具体目标如下:
1.Hadoop集群搭建,系统环境配置。
2.分析HDFS文件系统操作方面的实现过程。
3.阐释使用MapReduce编程实现对大量的日志文件处理,挖掘出所需要的日志信息。
2 技术背景
2.1认识Hadoop
2.1.1 Hadoop概述
Hadoop是Apache下的一个开源框架,可编写和运行分布式应用处理大规模数据。分布式计算是很宏大的研究方向,但Hadoop有如下几点不同之处:
方便——Hadoop运行在大型集群上,或者各种云计算服务商提供的云计算服务之上。
健壮——Hadoop致力于在一般商用硬件上运行。此类故障可以被解决。
可扩展——Hadoop通过增加集群节点,可以行之有效的提高它的处理效能,从而处理更大地数据集。
简单——Hadoop允许用户快速编写出高效的并行代码。
Hadoop的方便和简单让其在很多方面有非常大的优势,诸如编写和运行分布式程序。Hadoop集群的使用门槛大大的被降低。与此同时,它拥有令人信服的健壮性和可扩展性,这足以让很多大型的互联网公司放心的使用这套技术框架。这些特性使它在业界广受欢迎。
图2.1解释了如何Hadoop集群与客户机交互的情形。Hadoop集群是通过节点之间的,互连到网络上的一系列机器组。数据存储和处理在这个体系中完成。不同用户可以给Hadoop各自提交计算任务,这些客户端可以是与Hadoop集群远离的PC。
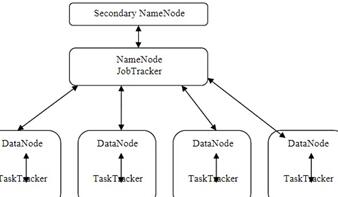
图2.1 Hadoop集群与客户机交互图题
2.1.2 Hadoop的结构组成
Hadoop的构造模块包括:
NameNode(名字节点);
DataNode(数据节点);
SecondaryNameNode(次名字节点);
JobTracker(作业跟踪节点);
TaskTracker(任务跟踪节点);
图2.2中描绘了一个典型Hadoop集群的拓扑结构。
-
JAVA基于安卓平台的医疗护工管理系统设计
-
基于Hadoop的制造过程大数据存储平台构建
-
php+mysql志愿者服务平台前端页面设计
-
《网站设计与管理》课程...
-
Justep基于开放平台的企业...
-
基于IOS的游戏资讯平台的设计与实现
-
android+mysql城市雨伞共享平台的设计与实现
电站锅炉暖风器设计任务书
当代大学生慈善意识研究+文献综述
java+mysql车辆管理系统的设计+源代码
杂拟谷盗体内共生菌沃尔...
河岸冲刷和泥沙淤积的监测国内外研究现状
十二层带中心支撑钢结构...
中考体育项目与体育教学合理结合的研究
大众媒体对公共政策制定的影响
酸性水汽提装置总汽提塔设计+CAD图纸
乳业同业并购式全产业链...