
14
3.3 基于PIDNN的AQM算法仿真实现 15
3.4 稳定性分析 17
3.5 本章小结 20
4 基于NS-2的AQM算法仿真 20
4.1 NS-2软件简介 20
4.2 仿真结果及性能分析 22
4.2.1 队列长度 22
4.2.2 瞬时丢包率 25
4.3 本章小结 27
结 论 28
致 谢 29
参考文献 30
1 绪论
近年来,Internet发展迅猛,速度几乎以指数方式增长。然而,巨大的成功和迅速的发展背后,自然而然会引发一系列的负面问题,网络拥塞就是其中一个重要而又无法回避的问题。近些年,随着网络拥塞现象不断增多,问题严重性不断突出,使得越来越多的人投身于这一课题的研究中来。
本章将会介绍网络拥塞的基本概念及其产生原因,之后将会介绍现阶段的网络拥塞控制方法和研究现状。
1.1 网络拥塞
通俗地讲,网络拥塞[1]就是网络在传输数据过程中产生了阻塞。一方面,在分组交换网络中传送分组数目过多导致网络负载增加,另一方面,网络本身的资源容量和处理能力有限,从而造成网络效率低下,网络拥塞也就产生了。网络拥塞的具体原因如下:(1)存储空间不足。(2)带宽容量不足。(3)处理器处理能力弱[2]。具体表现如下:网络的吞吐量受到影响同时效率降低、队列长度增大、丢包率和时延增加。首先,存储空间不足,那么在某个端口,数据流就会排队等候,一旦没有足够的存储空间,路由器缓冲队列就会急剧增加,后面的数据就会被丢弃。其次,带宽容量不足,对于低速的链路是无法承受高速数据流的输入的,这就会产生拥塞。最后,处理器处理能力弱,这个并不难理解,处理器处理的速度慢,跟不上高速链路,自然会产生网络拥塞。网络拥塞的现象可以直观的用图1.1来描述。
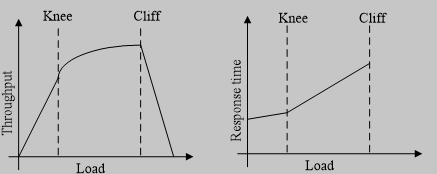
图1.1 网络负载的吞吐量及响应时间的关系
由图1.1可见,当网络负载较小时,吞吐量基本上随着负载的增长而增长,大致为线性关系,而响应时间增长缓慢;当负载增长到网络容量时,吞吐量增长缓慢,而响应时间急剧增加,这一点称为Knee;当负载继续增加时,路由器开始丢弃数据包,当负载超过也一定数量时,吞吐量就急剧下降,这一点称为Cliff。通常,Knee点附近区域被称为拥塞避免区间;Knee点和Cliff点之间被称为拥塞恢复区间;Cliff点之外被称为拥塞崩溃区间。
从全局来看,网络拥塞产生的原因有:(1)best-effort服务模型网络无法保证数据传输的服务质量;(2)由于没有“接纳控制”算法,网络无法根据网络资源的情况限制用户的数量;(3)Internet资源分布和流量分布的不均衡性,导致拥塞总是发生在资源相对短缺的地方。
值得注意的是,虽然拥塞是由于网络资源短缺引起的,但单纯增加资源非但不能避免拥塞的发生,有时甚至会加重拥塞程度[3]。例如,增加存储空间到一定程度,此时很可能只会加重拥塞,这是因为当数据包经过长时间排队完成转发时,它们很可能早已超时,源端便会进行超时重发。这些数据包将会继续传输到下一路由器,循环往复浪费了网络资源,也加重了网络拥塞。 基于神经元学习的自适应AQM算法及仿真研究(2):http://www.751com.cn/zidonghua/lunwen_71711.html